
Go 1.23 iterators
This summer, the Go team introduced new iterators, which, naturally, stirred up some controversy. Critics argued the design wasn’t very "Go-like"—too functional, too complex, and missing Go’s typical simplicity. A common complaint was: why not just introduce an iterator interface and allow range operations over it?
I get the criticism, and I agree to an extent. But the decision to go with push iterators over pull iterators makes sense too. It simplifies common tasks—like iterating over a database cursor—in a way that’s easier to write and follow than managing an iterator state machine.
For a function to act as an iterator, it has to follow one of three signatures:
func(func() bool)
func(func(K) bool)
func(func(K, V) bool)
And here’s the first challenge: you end up writing a function that returns another function, which takes yet another function. It’s a bit of a nesting doll situation.
Let’s break it down with this example:
func rangeIterating(it iterator[int]) func(func(int) bool) {
return func(next func(int) bool) {
for it.Next() {
if !next(it.Value()) { // handle break
println("break")
return
}
println("loop")
}
}
}
So, what’s calling what? What’s returning what? You’ve got a function (rangeIterating) that returns another function, which takes a function (next) as an argument. Inside, next gets called on each value from the iterator. It’s a mess of indirection: a function calls a function, which returns a function. It’s like untangling a pair of headphones you swore you left neatly coiled.
To make matters worse, in some examples they call the parameter function yield, which immediately clashes with languages like C#, Python, or JavaScript—where yield is a keyword that suspends and resumes execution.
Let’s simplify it by recreating for range behavior:
func myForEach(iterFunc func(func(int) bool), valueMapFunc func(int) bool) {
iterFunc(valueMapFunc)
}
All this function does is call the provided iterator function (iterFunc) with a valueMapFunc as its argument. The valueMapFunc is simple: it returns false when there’s a break in the loop, and true in all other cases.
Here are two snippets that essentially do the same thing:
it := &IntIterator{0}
for val := range rangeIterating(it) {
if val > 2 {
break
}
println(val)
}
it := &IntIterator{0}
myForEach(rangeIterating(it), func(val int) (falseIfBreak bool) {
falseIfBreak = true
if val > 2 {
falseIfBreak = false
}
println(val)
return
})
So, yes, the new for range loop isn’t iterating over a collection itself. Instead, it expects the iterator function to handle the looping. The for range just receives values via the value mapping function. The iteration logic is offloaded to the iterator, with for range acting as a receiver for whatever values the iterator decides to pass along.
Here’s a full sample you can play with:
package main
type iterator[T any] interface {
Next() bool
Value() T
}
type IntIterator struct {
Val int
}
func (it *IntIterator) Next() bool {
it.Val++
return it.Val < 10
}
func (it *IntIterator) Value() int {
return it.Val
}
func rangeIterating(it iterator[int]) func(func(int) bool) {
return func(next func(int) bool) {
for it.Next() {
if !next(it.Value()) { // handle break
println("break")
return
}
println("loop")
}
}
}
func myForEach(iterFunc func(func(int) bool), valueMapFunc func(int) bool) {
iterFunc(valueMapFunc)
}
func main() {
it := &IntIterator{0}
for val := range rangeIterating(it) {
if val > 2 {
break
}
println(val)
}
it.Val = 0
myForEach(rangeIterating(it), func(val int) (falseIfBreak bool) {
falseIfBreak = true
if val > 2 {
falseIfBreak = false
}
println(val)
return
})
}
In the end, we didn’t really gain any groundbreaking capabilities with this change. I still wish we had something cleaner, like:
for k, v := range iteratorStruct {
}
But we’re still have:
for iteratorStruct.Next() {
}
And let’s be honest—this is still way better than the C++ iterator interface. Go’s approach might feel a little unconventional, but at least it’s easy to implement and far less painful than C++’s monstrosity.
Automating Local Processes with Ollama
Since the release of GPT-3, large language models (LLMs) have become integral to daily life. When OpenAI introduced a user-friendly chat interface, many jumped to predict the end of human involvement in various professions: software development, writing, editing, translation, art, even CEO, CFO CTO roles. While some still cling to these predictions, it's unlikely to happen anytime soon. However, LLMs are undeniably valuable tools.
Can LLMs Help with Software Development?
The simplest answer is to use something like GitHub CoPilot, which writes code for you. I've tried it and wasn't blown away. Sure, it can produce code better than a lot of low-quality attempts I've seen in over 20 years in the industry, but it's far from the best. Its output is mediocre, but does it really need to be perfect? Is it even solving the right problem? Is writing the code even the main bottleneck in software development? Not really. Most of a developer's time is spent reading code and navigating organizational hurdles, comprehending system design, looking for a defect in a system that does not produce any logs but still runs on production, not typing code. And yes, maybe some of those problems will be addressed with more advanced frameworks like AutoGen
While CoPilot can bridge gaps in a developer’s API knowledge, it struggles to keep up with the latest changes in packages. Microsoft is working hard to address this, but it remains a weak point. In my experience, CoPilot's autocomplete is inconsistent, and I often found myself spending more time fixing its output than thinking critically about the problem I was trying to solve. All this, coupled with the high price tag, left me unimpressed. Microsoft likely doesn’t even break even with what they charge, so expect prices to rise as the service matures.
Privacy Concerns
Another issue with specialized tools like CoPilot is privacy. Sure, there's a EULA, but in most cases, sensitive data needs explicit authorization to leave a protected environment for anything beyond hobby projects. CoPilot isn’t ideal in this regard. IntelliJ's recent attempts at local models are noble. same applies to everything that was done for VIM and Emacs (ok, ok... for VS Code too).
Flexibility and Customization A final frustration is how these models are locked into specific use cases. If your needs deviate from the product manager’s roadmap, you're stuck. Wouldn't it be nice if you could have a model that works in any custom scenario, without navigating API limitations?
This brings us to Ollama.
Why Ollama?
What if we had a tool that accepted any text input via stdin and produced stdout like traditional UNIX utilities—grep, awk, sed—but with some intelligence applied? That's where Ollama comes in. It's been around for a while, and many developers already use it.
Getting Started with Ollama
To install it on Linux:
curl -fsSL https://ollama.com/install.sh | sh
On Windows and macOS, head to Ollama's homepage, download the installer, and follow the standard process. (At the time of writing, there’s no Chocolatey package, and I haven’t checked Homebrew.)
Once installed, you can run:
ollama run mistral
This downloads around 4GB of pre-trained model weights and starts a session with the Mistral model, which I’ve found to be solid for software development tasks.
But this is old style fun, just without web interface, how about that serious bash scripting?
Let's start with something simple like
echo "`git diff 01e0ca images.go` write a message for git log using only the data you were provided" | ollama run mistral

I take git diff for a file and supplement it with a direction to the model, and the result is not bad. Much better than a log of messages in git log I saw. So no more generic change messages?
But can it be even better? Let's set a mark to the quality of the comment:
DIFF=`git diff goGet.go`
GITLOG=`echo "$DIFF write a message for git log using only the data you were provided" | ollama.exe run mistral`
SCORE=`echo "Score 1-10 if this is an informative git log message. Use only this data and return only one number. Don't explain. $GITLOG" | ollama.exe run phi3:medium`
echo "$SCORE"
And I got result 7 on a first run, 8 on the second. I can keep trying until its perfect or settle for anything less than that. And all of that can be done hands-off.
So sky is the limit.
Wait, but what if my machine (a laptop) is too weak to run a decent model like phi3:medium, or even the small ones take forever to generate? Am I out of luck and have to depend on greedy API providers?
First of all, you can use something like an external GPU if your machine supports either
- Thunderbolt 3+
- Oculink
- Has one unused nvme ssd m.2 port
get a GPU with as much VRAM as you can afford and enjoy.
What if my machine does not support any of that?
You can always run ollama server on a different machine. It is controlled with an environment variable
OLLAMA_HOST=hostname:port
You can make ollama available within your protected network by setting simple magic in your nginx (DON'T use that on production)
location / {
proxy_pass http://localhost:11434;
proxy_set_header Host 127.0.0.1;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for;
}
And for a server you can get anything starting from a used laptop or a desktop that you can get for cheap, or you can rent hardware from cloud providers (which is more convenient, but hugely more expensive)
And yes. Ollama exposes REST api that you can use. But that is simply stated on their own documentation page.
curl http://localhost:11434/api/generate -d '{
"model": "llama3.1",
"prompt":"Why is the sky blue?"
}'
SAFe or Scaled Agile Framework
What is SAFe?
Many people are familiar with the concept of Agile. Even more people involved in IT use the terminology. And even more have heard about Agile.
However, not everyone who confidently uses the term "Agile" for communication, critique, or to present their team or company in a better light understands, for example, the difference between SCRUM and Agile. Often, they equate these two distinct concepts. But in 2015, a new term emerged—SAFe. What is it, and why is it necessary?
One of the key advantages and disadvantages of SCRUM, in my opinion, is the prescribed team size—7±2 (or 3-9 according to the latest Scrum Guide), including the Product Owner. Certainly, 9 highly skilled and well-motivated professionals are capable of achieving a lot, but sometimes, there is a need to build something that requires more hands, heads, eyes, and brains, in the end. Expanding teams is a bad idea, which means that the number of teams must increase. However, this introduces the problem of communication between teams, synchronization of work, and SCRUM itself does not offer a solution for these issues. There have been attempts to manage SCRUM at the level of SCRUM teams (as recommended by Jeff Sutherland, one of the authors of the Agile Manifesto), there’s Large Scale Scrum, Disciplined Agile Delivery, and many other methods, but there is also SAFe—Scaled Agile Framework.
SAFe is a framework for managing a company where coordination is required for work on a project or related projects involving 5 or more SCRUM teams. It acts as a layer on top of SCRUM, enabling the management of groups consisting of 100 or more people.
The benefit?
First and foremost, this methodology is, of course, beneficial to those who sell it and offer training on it. Dave Thomas (another author of the Agile Manifesto) commented on this topic quite well during his presentation Agile is Dead at GOTO 2015.
Secondly, program management departments. Those who used to manage projects, obtain PMP certifications, create Gantt charts, and implement the concept of firm-soft management (soft towards leadership and firm towards executors) now find a role in SAFe. The issue is that in typical SCRUM, there is no function for them, but in SAFe—there is. The same applies to various types of architects. In SCRUM, there is no function for them, but SAFe provides a clear career path.
Next, it could be beneficial to business owners whose managers work on large projects that consume an enormous amount of man-hours and who cannot (sometimes for objective reasons) make these projects independent.
Also, for a large number of developers with below-average qualifications, since often, exponentially more of them are needed to accomplish something compared to those same experienced and motivated professionals.
In general, it benefits the industry. Since the number of developers doubles every 5 years (see Uncle Bob's Future of Programming), the consequence is that at any given time, at least half of the developers have less than 5 years of experience. If this trend doesn’t change, and it seems it won’t, processes are required to prescribe and formalize their work functions, mechanisms of interaction between participants, and overall processes.
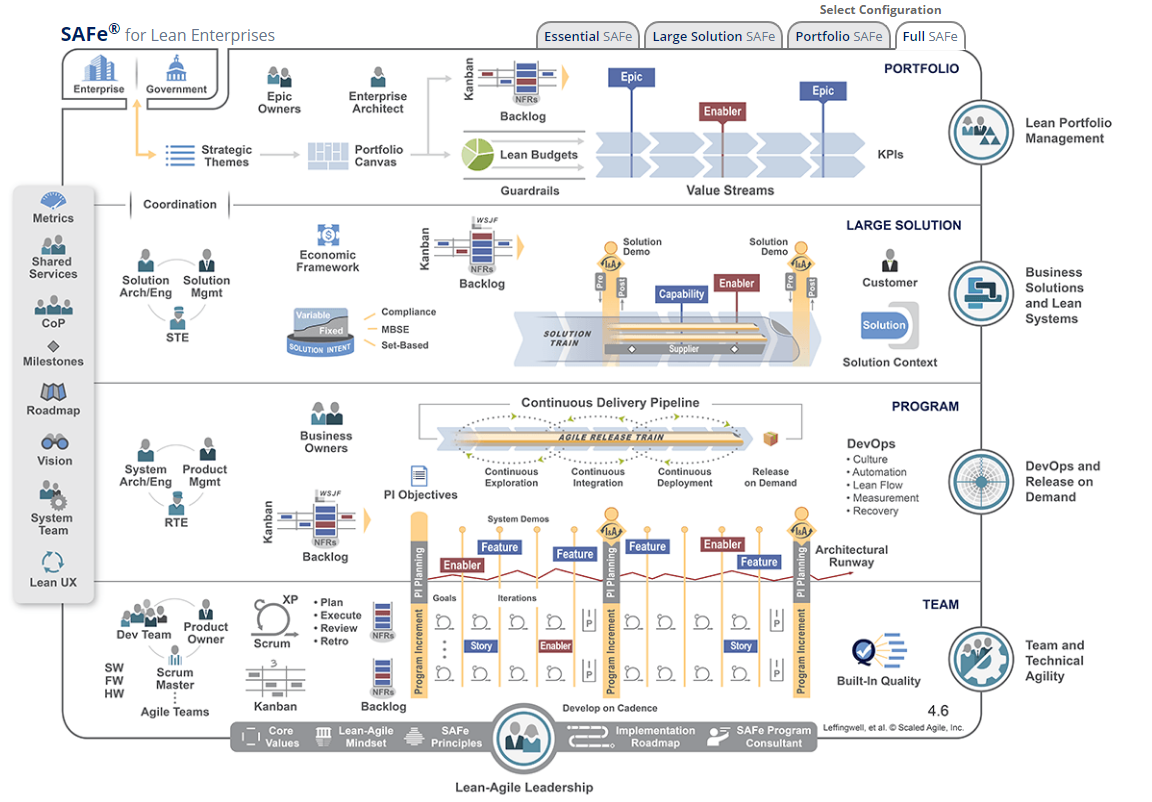
SAFe is like a multi-layered cake of various Agile methodologies. At the bottom level is a nearly traditional SCRUM with typical two- to three-week sprints and teams of 3-9 people, including the Product Owner. All the standard rituals are in place, from the daily standups to the retrospective meetings. However, there is one key difference: the team ceases to be a fully functional, independent unit, and the sprint is no longer an independent time block with a complete lifecycle. Sprints are grouped into Program Increments (PIs), usually consisting of five sprints. So, if in classical SCRUM we build something the client doesn’t like, we can correct the course in the next sprint. But in SAFe, we continue heading toward the cliff until the end of the Program Increment, potentially up to the next four sprints (of course, I’m exaggerating a bit).
At the next level, we have the trains—the so-called Agile Release Train (ART). To manage these five-sprint segments, new roles emerge—System Architect (who owns the architecture, meaning the team no longer does), Product Manager (who manages the product, and not the Product Owner, who now seeks advice from the Product Manager), and RTE (Release Train Engineer, essentially the PMP from the waterfall world). Some Kanban practices are applied here, like boards, prioritization methods, and the principle of measuring historical team performance (velocity). Projections of what will be built by the end of the time block are made, as opposed to setting deadlines for fixed functionality (scope). One innovation is that the final sprint of the five is declared an organizational sprint. During this sprint, massive meetings are held (with all teams—100+ people), technical debt is analyzed, plans for architecture work are developed, and all teams synchronize their work.
Above the train level is the coordination between departments, directors, and the client. This level borrows heavily from Lean Agile while retaining Kanban tools. Here, an analysis of the economic feasibility of changes takes place. Ideally, any change undergoes a preliminary analysis, where a measurable hypothesis about the upcoming change is proposed (for example, "if we move the online store from a data center to the cloud, we will be able to increase the number of transactions by 10% during peak seasonal sales by rapidly scaling capacity"). This hypothesis is then either confirmed or rejected. For companies with less than a billion dollars in revenue, this might be the highest layer. This level also involves planning work for the next 12-36 months (hello to five-year plans for quality, quantity, etc.).
Above the large systems level is portfolio management. Here, funds are allocated to various business areas using Lean Portfolio Management. Based on the company’s development strategy, directions are chosen that offer potential returns. Decisions are made about acquisitions or mergers with other companies, creating new business areas, or shutting down old ones. Budgets are regularly adjusted and reallocated (in contrast to quarterly or annual plans). For each portfolio component, a set of more or less standardized metrics is defined, and everything is evaluated based on them. As with the previous three levels, there are special synchronization rituals every two weeks (usually), where status updates and key indicators are exchanged.
At the very top is the strategy. However, the framework does not describe how this strategy is determined.
Advantages:
- A significant number of quite useful tools (WSJF, Kanban, Gemba, etc.).
- Steps for the SDLC (Software Development Life Cycle) are formalized and prescribed, starting from writing code (TDD is recommended) to static scanning, CI/CD, and feature toggles. Whether each practice is good or not is another question, but at least there is a plan, and everyone follows it.
- The process is understandable, explainable, and implementable.
- Every person in this process is assigned a well-defined role.
- The company becomes more transparent for those who work in it.
Disadvantages:
- It takes a relatively long time to respond when expectations do not match reality.
- A huge amount of resources and money is spent on communication and meetings.
- Often, the recommended solutions within the framework are outdated.
Should it be implemented?
In my opinion, if there’s a choice—no, it’s better to reduce dependencies between departments and projects. But if there’s no choice and you need to manage a massive project, then it’s definitely a viable option.
this is translation of my article written in 2018